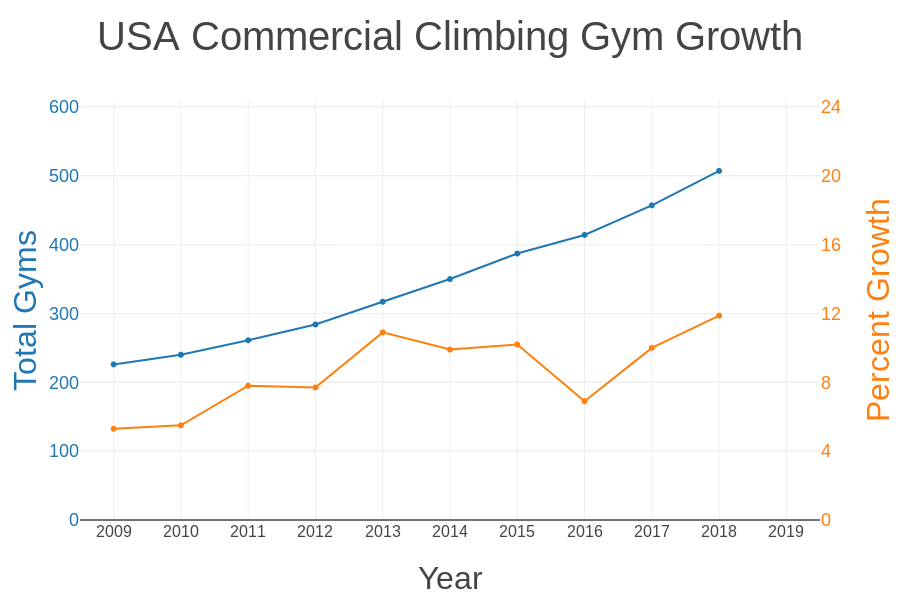
Rock climbing is one of the fastest growing sports in the world. According to the Climbing Business Journal, the establishment of new climbing gyms in the United States is currently in exponential growth, with an estimated 100 new gyms opening between 2018 and 2020 to meet the growing demand of new climbers. As a Data Scientist and a rock climber, I wondered if there was any data-driven business insights I could deliver to new gym owners using my toolbox of data science techniques.
Yelp is an online directory in which users can publish reviews on businesses. It is often a great resource for first-time visits to new areas. Using Yelp reviews, I wanted to see if I could use some natural language processing techniques to be able to categorize reviews and come up with a list of do’s and don’ts for climbing gyms in California.
Data Acquisition
Since Yelp releases a new competition dataset each year in JSON format, I felt this was the right place to start. The entries in the competition dataset are structured like in the two following examples.
# Review
{'review_id': 'vgXITaQ2uK28PMET91KuVg',
'user_id': '8dpqRMuHRnPwJPzyUp1nwA',
'user_name': 'Kristina S.',
'business_id': 'ImFFWa6UEu_fhfODG1yBiQ',
'stars': 4,
'useful': 2,
'funny': 0,
'cool': 0,
'text': "I really loved this place!! We came here to celebrate my cousin's birthday. What better way to celebrate a birthday than to climb some rocks. Lol. Anyway, parking was no problem, and it's pretty easy to find. We checked in, signed some waivers then took our beginner course with Jonny, since we are all noobs. He was very nice and helpful. Everything made sense and in 30 minutes or so, my group and I were confident to take on the rocks!If you're looking to have some fun and also to challenge yourself (because rock climbing isn't easy), you should check this place out. I'd love to come back.Deducted a star because some of the ropes are a little smelly. I feel like they should clean more often? or replace more often. Just a suggestion for management. Other than that, this place would've been a solid 5 stars.",
'date': '3/18/2017'}
# Business
{'business_id': 'ImFFWa6UEu_fhfODG1yBiQ',
'link_id': 'diablo-rock-gym-concord-3',
'name': 'Diablo Rock Gym',
'address': '1220 Diamond Way Ste 140',
'city': 'Concord',
'state': 'CA',
'postal_code': '94520',
'telephone': '+19256021000',
'latitude': 37.9655526,
'longitude': -122.0532716,
'stars': 4.0,
'review_count': 144,
'is_open': 1,
'attributes': {'Accepts Credit Cards': 'Yes',
'Parking': 'Street, Private Lot',
'Bike Parking': 'Yes',
'Good for Kids': 'Yes',
'Dogs Allowed': 'No'},
'categories': 'Gyms, Yoga, Climbing',
'hours': {'Mon': '5:30 am - 10:00 pm',
'Tue': '5:30 am - 10:00 pm',
'Wed': '5:30 am - 10:00 pm',
'Thu': '5:30 am - 10:00 pm',
'Fri': '5:30 am - 10:00 pm',
'Sat': '9:00 am - 6:00 pm',
'Sun': '9:00 am - 6:00 pm'}}
This is great, because all of the files contain the business_id, which can be used to join them together if necessary. However, this also has some drawbacks, since I also wanted data that was up-to-date.
Next, I looked into Yelp’s newest API, called Yelp GraphQL, which enables users to enter queries and return the results all in JSON. Yelp even has an online console where you can send such queries. For data science projects, it is also easy to use an ipython notebook to make queries after a simple setup.
Unfortunately, there was an enormous drawback to using the Yelp API, which I found out about it only after hours of setup and learning about GraphQL: Yelp’s API is extremely limiting. There is a hard limit of 3 results per query, and review text is limited to 150 characters per review. This is so much less data than simply accessing the data as html through the website that it makes the Yelp API effectively useless to any normal user. I make special mention of this limitation, because it was not obvious at all from reading Yelp’s documentation, and hopefully, you did not also go through the same process only to be unrewarded in the end.
Because of these limitations, I found that the only easy way to access the data that I wanted was to scrape it using Beautifulsoup4. I sought to stay as close as possible to the format that Yelp already made available through their challenge dataset, so that it would be as if I was working with data that Yelp handed to me directly.
Here are the scrapers I built for reviews and for business information, in case you would like to adapt them to your purposes. In order to use them, I made a list of urls of all the climbing gyms in California, which I sought to analyze. Finally, for easy access, I concatenated the data so I could do some exploratory data analysis.
Exploratory Data Analysis
To understand what data I would be working with, I made some simple visualizations and learned the following facts:
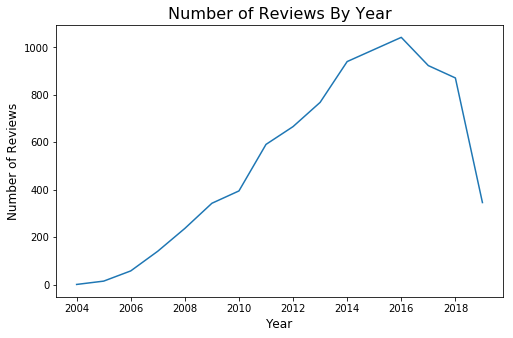
A) The total number of reviews had been declining in the last three years. In my opinion, the most-likely reason is that new visitors do not feel the need to add more reviews to the already-existing corpus.
B) Reviews are skewed heavily toward 5-star reviews. This is reflective of the overall trend on Yelp in general, as most businesses follow this kind of a distribution.
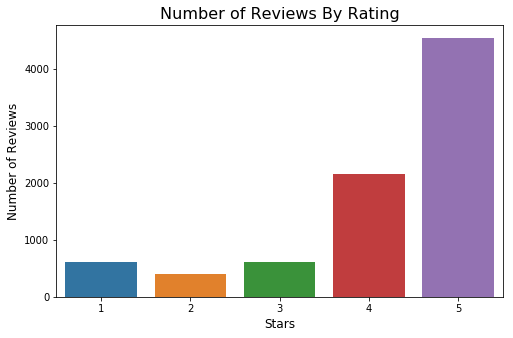
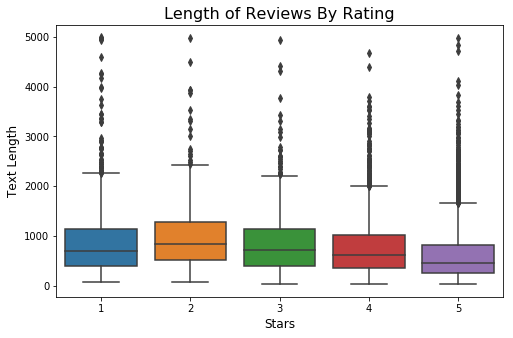
C) There is a negative correlation between the length of the review and the star rating.
D) The other features offered by Yelp have a weak correlation with the star rating.

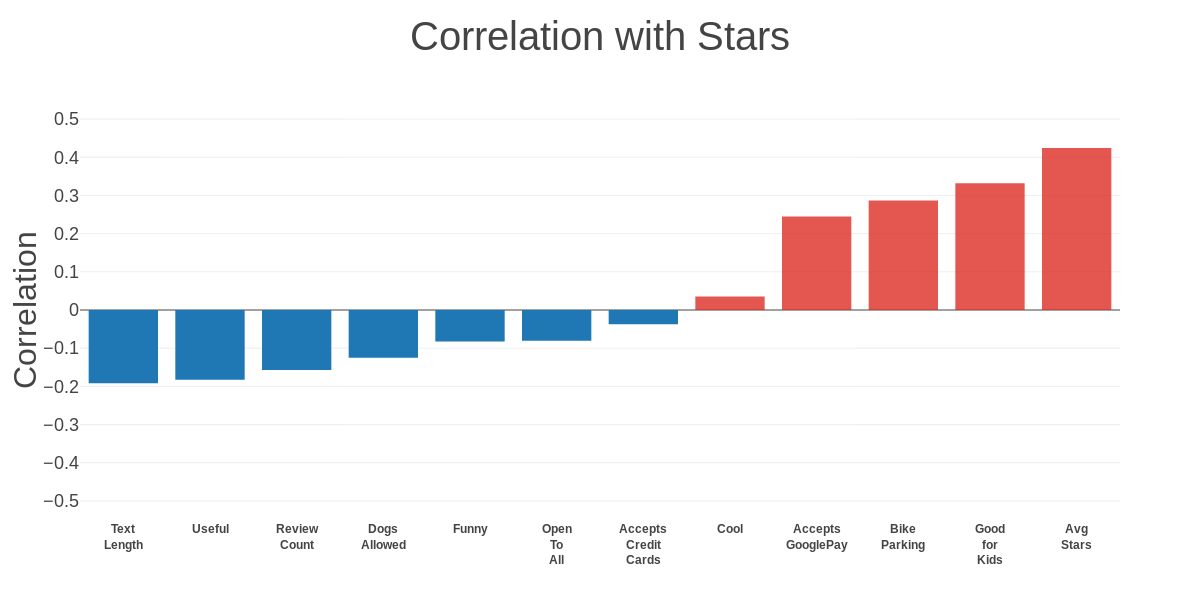
Classifying Reviews on Text
Gym owners will likely receive more spoken reviews than written ones, and they may also receive unlabeled reviews if they includes comments and suggestions box in their gyms. If they record these data for downstream applications, such as topic-modeling, it will be important for them to be able to correctly classify reviews according to the star rating, especially given the decline in the number of reviews after 2016 in the Yelp dataset. The problem of classifying reviews into five categories is multi-class classification problem and is a classic technique of machine learning. Let’s see how this works.
The first step in any machine-learning process is always to set aside some data that must remain untouched while training the model. Only on testing on an out-of-sample test set is it possible to estimate how well the model can generalize to data it has never seen before. I found that 20% of the data occurs after May 28th, 2017, so I split the dataset into a training set of data prior to this date and a test set of data after this date.
For text processing, in order to work with the text, it must be tokenized, or converted into individual words which make up the features for the classification. I found that sklearn’s count-vectorizer outperforms TF-IDF, and that keeping an n-gram range of 1 to 3 gives the best performance in terms of speed and accuracy. Also, I removed the standard stop-words to avoid having the model be trained on useless features.
# Count Vectorizer
count_vectorizer = CountVectorizer(ngram_range=(1,3), stop_words='english')
With the above setup, I can build a logistic regression classifier, which is a good first-choice for natural language processing. To get an overview of the model accuracy on the test set, I generated a confusion matrix, which is a table that shows how many items from each class were correctly classified. For example the confusion matrix below shows that 963 5-star reviews were correctly classified, 109 5-star reviews were mis-classified as 4-star reviews, and the rest were mis-classified as 3 or below.
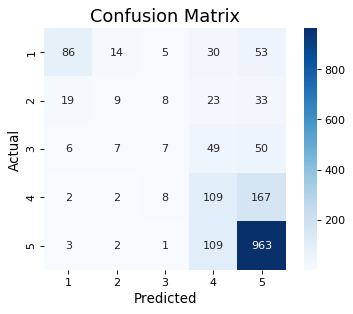
Let’s see how well this model performs on the test set using the following two metrics: micro-average and macro-average accuracy.
Micro-Average Test Accuracy: 0.6651558073654391
Macro-Average Test Accuracy (+/-1): 0.6866352509102764
The micro-average test accuracy is the total number of correctly classified reviews divided by the total number of reviews. In this case, 1174 out of 1765 reviews were classified correctly, giving a score of 0.6652. The macro-average test accuracy is the average of the accuracy for each class, within one class. Both of these metrics seem similar now, but it will later be apparent why only the macro-average test accuracy can be used to show model improvement.
In this initial model, it is apparent that the classifier is great for 1- and 5-star reviews, but suffers for anything in between. This is very easy to see in the graph below, which shows what fraction of predictions fall in each category for each type of review. For example, looking at the purple curve, approximately 0.9 of 5-star reviews were correctly classified as being 5-stars, and approximately 0.1 of 5-star reviews were mis-classified as 4-star reviews.
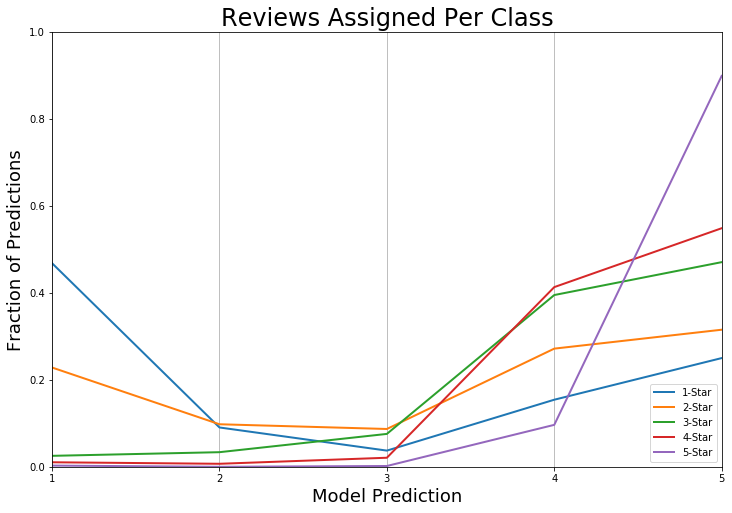
The performance of this classifier is great if the goal was only to separate positive from negative reviews. However, if the goal is to have finer granularity for purposes like sending coupons or advertisements to people who give 2- and 3-star reviews, but not 1-star reviews, then this classifier falls short.
How do we fix this issue?
One way to correct for predictions from logistic regression is to add a weight matrix, where the importance of minority classes is increased according to the new weights. For multinomial logistic regression, scikit-learn recommends having class weights that are inversely proportional to the size of the classes.
# Class Weights
count_dict = Counter(target_train_ser)
class_weight = np.array([1/count_dict[1], 1/count_dict[2], 1/count_dict[3], 1/count_dict[4], 1/count_dict[5]])
features_train_vectorized_proba_array_new = normalize(features_train_vectorized_proba_array * class_weight, axis=1, norm='l1')
Let’s see if using the new weights improves our classifier by looking at our confusion matrix.
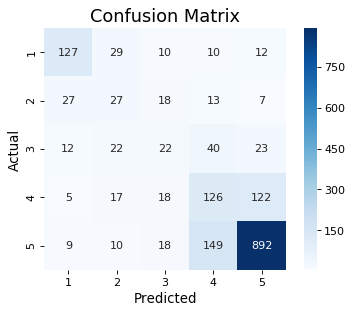
As can be seen in the confusion matrix above, the model is now better at classifying across the board, except for 5-star reviews, which took a minor drop in performance. This is reflected in our accuracy scores below.
Weighted Micro-Average Test Accuracy: 0.6764872521246459
Weighted Macro-Average Test Accuracy (+/-1): 0.8415133147419817
If you only look at the micro-average test accuracy, the improvement might appear to be insignificant. However, this demonstrates that the macro-average test accuracy is a better metric for measuring the performance of the classifier. As seen in the graph below, except for 3-star reviews, the correct classification now makes up the majority of the predictions for each class.
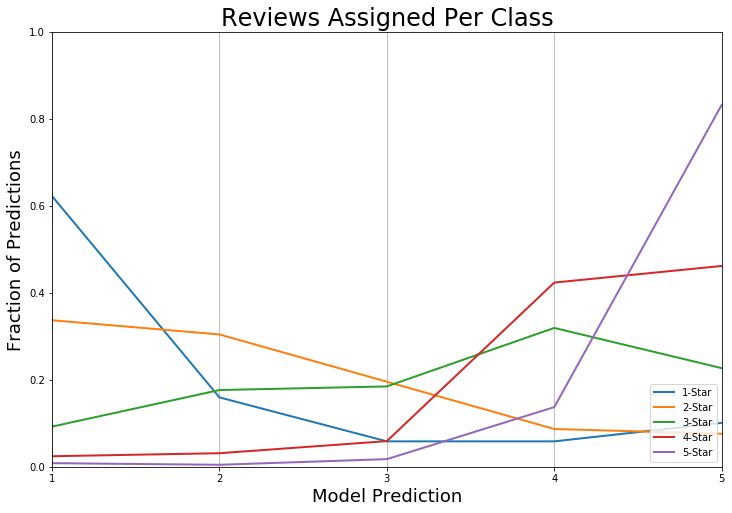
Evaluating Performance
As another measure of performance, we can examine the ROC curves for the individual classes.
A ROC curve plots the false positive rate (FPR) on the x-axis and the true positive rate (TPR) on the y-axis. The curve is generated by considering all thresholds for each classification. For example, a random guess is represented by a diagonal line, since there, FPR and TPR are equal. Models that perform better than a random guess are pushed up toward the top left corner, since this is the space in which the TPR is higher than the FPR.
The ROC curve has an additional probabilistic interpretation that the Area-Under-the-Curve (AUC) is the probability that given a random positive-negative pair that the classifier will classify each correctly. For example, given a 2-star review and a 5-star review, the classifier will correctly classify the 5-star review with probability 0.8719.
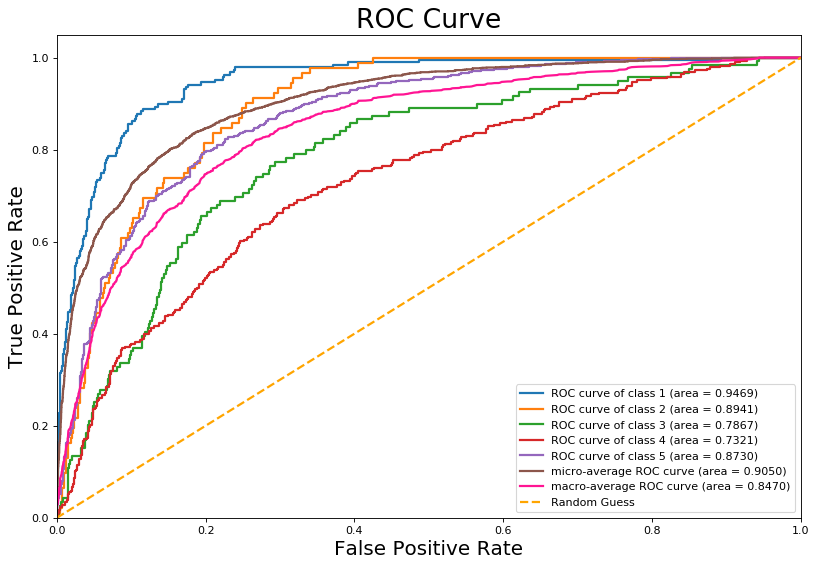
In addition to the individual ROC curves, it is possible to calculate a micro-average and a macro-average ROC curve, using similar procedures as with the accuracy score calculations. However, similar to before, the micro-average ROC AUC is an overestimate, because it is skewed by the enormous number of 5-star reviews in the dataset. Hence, the macro-average ROC curve is a better measure of performance, since it is a measure of how well the model will perform given a balanced dataset.
Including Categorical Features
Along with the text of the main review, Yelp also provides additional features that may help users determine which reviews to read. For example, other users can vote on whether a review is useful, funny, or cool, and businesses can list whether they allow dogs or if they have bike parking. As an improvement on simply using the review text alone, I wanted to see if by combining these additional features, I could improve my classifier. For this purpose, sklearn’s Feature Union helps to concatenate features, and sklearn’s Pipeline tool helps to organize the training phase succinctly.
By combining the following list of features, let’s see if we can get an improvement in the modeling.
feats = FeatureUnion([('count', count),
('tfidf', tfidf),
('text_length', text_length),
('useful', useful),
('review_count', review_count),
('Dogs Allowed', dogs_allowed),
('funny', funny),
('Open to All', open_to_all),
('Accepts Credit Cards', accepts_credit_cards),
('cool', cool),
('Bike Parking', bike_parking),
('Good for Kids', good_for_kids),
('avg_stars', avg_stars)])
# Create the pipeline
pipeline = Pipeline([
('feats', feats),
('logreg_mlt_pipe clf', LogisticRegression(multi_class = 'multinomial', solver = 'newton-cg')),
])
And the improvement is…
Micro-Average Test Accuracy: 0.6764872521246459
Macro-Average Test Accuracy (+/-1): 0.6907512934391933
Weighted Micro-Average Test Accuracy: 0.6719546742209632
Weighted Macro-Average Test Accuracy (+/-1): 0.84267517676204
… insignificant. Even though there was a minor improvement, it’s hard to justify adding these additional features into the model given that it increases how long it takes to train the model.
Despite that these particular features did not give a significant improvement, I still want to emphasize the power of sklearn’s Feature Union and Pipeline tools. If a gym owner receives a hand-written comment in their comments box and hand-labels it before entering it into a database, this additional hand-labeled feature could be very important for predictions and should be added to the classifier using sklearn’s Pipeline.
Topic Modeling
After classifying reviews according to their star ratings, I am now ready to derive some business-related insights from those reviews. While I could potentially gain the same insights by randomly the reviews, this is not without problems. First, I do not have all the time in the world to read through 8000 reviews. Second, if I pick random reviews to read, due to the class imbalance of the dataset, I will end up reading too many 5-star reviews and not enough 3-star reviews. Third, even if I were to read through all of the reviews, as a human being it will be difficult for me to figure out which topics are most important. What is difficult for me as a human turns out to be trivial for a machine. The problem of extracting the most important topics from text is topic modeling, which is a classic technique of natural language processing.
The procedure for topic-modeling is simple. Like before, the words of the review text should be transformed into individual features using count-vectorizer or TF-IDF. I found that for topic-modeling, TF-IDF gave better results. I also kept an n-gram range of 1 to 3 and removed the standard stop-words. This results in a matrix with 8317 rows and 720127 columns, where each row represents an individual review, and each column represents a word or group of words. The entries of such a matrix are the number of times these words appear in the text.
Using a technique called non-negative matrix factorization, the algorithm will factor this 8317x 720127 into two matrices depending on the number of topics specified. I chose to factor the matrix into 10 topics, so the algorithm will return two matrices, an 8317x10 matrix and a 10x720127 matrix. By accessing the first few elements of the 10x720127 matrix, one can figure out which topics are the most important.
5-Star Reviews
The following are the two most important topics for 5-star reviews, limited to 100 words or group of words.
Topic 0
rock, rock climbing, time, climb, belay, fun, day, class, kids, try, wall, walls, friend, definitely, got, pass, did, went, experience, sure, come, shoes, different, pretty, instructor, took, came, easy, didn, lesson, day pass, harness, just, groupon, safety, recommend, super, way, party, make, little, hour, rope, free, wanted, facility, friends, doing, want, use, climbed, hold, birthday, rock climb, indoor rock, belaying, difficulty, old, rock climbing gym, patient, course, ll, indoor rock climbing, group, hours, sore, courses, city, loved, deal, don, said, looking, able, rock city, make sure, time rock, son, intro, going, thanks, think, hands, tie, heights, indoor, let, people, felt, rental, test, decided, levels, lot, rocks, person, chalk, wait, night, bring
Topic 1
gym, climbing gym, gyms, best, climb, new, people, good, home, friendly, ve, love, just, clean, climbers, gym ve, problems, membership, better, equipment, regular, staff, community, setting, love gym, nice, small, come, open, favorite, home gym, variety, lot, really, isn, weights, climber, friends, la, rock climbing gym, make, bouldering gym, members, bay, makes, san, awesome, gym climbing, far, parking, area, training, touchstone, rock gym, say, gym great, sure, gym area, happy, gym equipment, city, machines, best gym, doesn, boulder, feel, great gym, new gym, regular gym, huge, gym membership, decent, especially, probably, years, best climbing gym, beginners, auto, workout, work, look, gym pretty, cliffs, seriously, busy, best climbing, offers, walls, local, ll, gym really, cool, gym just, enjoy, large, style, different, gym gym, price, offer
For topic 0, from the presence of words such as pass, day pass, lesson, groupon, and birthday, it is possible to infer that these reviews were written by people who were only at the gym for a day. Likewise, reviews in topic 1 was likely written by people who are regular members due to the presence of words such as best, friendly, regular, community, gym area, regular gym, gym membership, etc.
To help visualize these in a nicer way than having a simple list of words, I used the word_cloud library to generate the following word clouds.
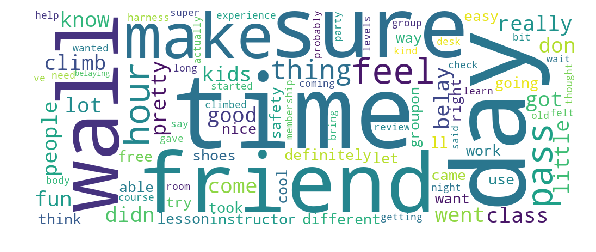
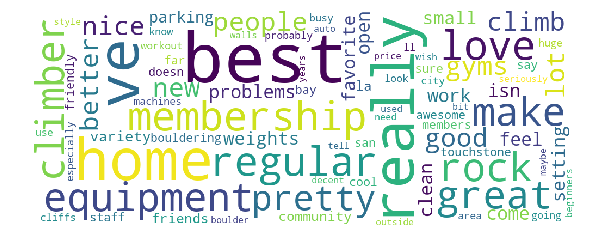
These visualizations give a quick overview of the target populations. If you are a gym owner hoping to attract more 5-star reviews, these are two populations for which to focus on.
1-Star Reviews
The following are the two most important topics for 1-star reviews, limited to 100 words or group of words.
Topic 0
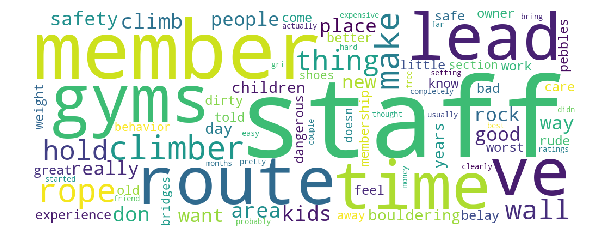
gym, climbing, belay, routes, staff, rope, climb, gyms, rock, ve, climbing gym, just, area, lead, place, don, bouldering, test, holds, route, climber, like, climbers, way, people, time, safety, really, new, ropes, good, worst, set, walls, hold, feel, years, rock climbing, know, wall, better, mesa, partner, member, experience, want, mission, cliffs, technique, lead climbing, tape, rock climbing gym, used, staff member, belaying, mission cliffs, members, doesn, make, climbing gyms, unsafe, seen, love, going, look, pretty, probably, gri, climbs, old, great, rude, tie, dirty, safe, far, maybe, bay, did, climbing years, actually, boulder, belay test, started, went, san, fall, hard, long, kids, harness, weight, need, use, thing, setting, rock gym, bouldering area, work, real
Topic 2
youth, continue, program continue, comps, program continue host, youth comps nearly, comps nearly impossible, comps nearly, impossible youth, impossible youth team, climbing program continue, climbing program, host youth comps, team continue, host youth, nearly impossible youth, continue host, nearly impossible, continue train, youth climbing program, youth comps, youth team continue, team continue train, youth team, continue host youth, cut youth, cut youth climbing, youth climbing, host, program, train, team, nearly, cut, impossible, climbing, toddler, area, toddler area, park, nice want, beware debit card, membership friendly nice, friendly nice, continue charge, membership friendly, request cancel membership, request cancel, cancel membership friendly, debit card continue, continue charge repeatedly, repeatedly request, repeatedly request cancel, charge repeatedly request, card continue charge, charge repeatedly, beware debit, card continue, friendly nice want, debit card, debit, repeatedly, know expect, little, argumentative, request, really lame toddlers, really lame, expecting climb like, area year, kept asking play, climb like park, like park, like park tiny, useful, useful older, useful older kids, need toddler way, climb little, need toddler, area useful older, climb little area, going class need, going class, climbing structures, park expecting, old kept asking, asking play, asking play weight, lame toddlers, lame toddlers adept, foam blocks climbing, foam blocks, expecting climb, short impossible, area year old, short impossible climb, way pay wish, year old kept, way pay
Topic 0 seems to be generically talking about the facility, for example, holds or rope being old and dirty. Topic 2 is a mix of youth team taking up too much space for competition practice and not enough supervision for toddlers, possibly leading to people wishing to cancel their membership or get a refund. The following word clouds may be somewhat easier to read.

Conclusion
By building my own Yelp scraper, I was able to collect reviews on climbing gyms in California. Using multi-class logistic regression, I was able to classify reviews as being 1-, 2-, 3-, 4-, or 5-stars with high accuracy. I was also able to improve the performance of this classifier by giving the minority classes more importance, which improved my out-of-sample test accuracy from 0.687 to 0.842. It may be possible to derive further improvements using sklearn’s Feature Union and Pipeline tools and a collection of hand-labeled reviews.
I also used the natural language processing technique of non-negative matrix factorization to extract the important topics for 1- and 5-star reviews and derive some take-home messages for new gym owners looking to improve their gym. These insights may help new gym owners figure out which groups of people to target for deals or how to best maximize their budget to derive the most meaningful improvements to their gyms.
Future Work
Although my work can deliver insights, there is a lot of room for improvement.
One way I could improve the classifier is to incorporate the use of Google’s Word2Vec in order to replace n_grams with word2vec vectors as the primary features. The advantage of this approach is to greatly reduce the dimensionality of the dataset, because similar concepts, such as climbing and “rock climbing” will be bundled together, making the model easier to train and test.
To improve the classifier, I hypothesize that I would have more similarity within topics if I used the star ratings predicted by my classification model rather than the hand-labeled star ratings, although I imagine that the business insights derived from both approaches will be similar.
If you’re interested, please check out the Github repository here. Thank you for reading, and I hope enjoyed this post!